 I2D2:Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
I2D2:Inductive Knowledge Distillation with NeuroLogic and Self-Imitation
"Scale is not the only way"
Small LMs can not only match, but outperform the commonsense ability of large LMs when supplemented with algorithmic techniques.
Downloads
| I2D2 Iteration 0 |
I2D2 Iteration 1 |
I2D2 Iteration 2 |
|
|---|---|---|---|
| Generator | LINK | LINK | LINK |
| Discriminator | LINK | LINK | LINK |
| Gen-A-tomic Corpus | LINK | LINK | LINK |
| Annotated Data (for training discriminator) |
LINK | LINK | LINK |
Framework
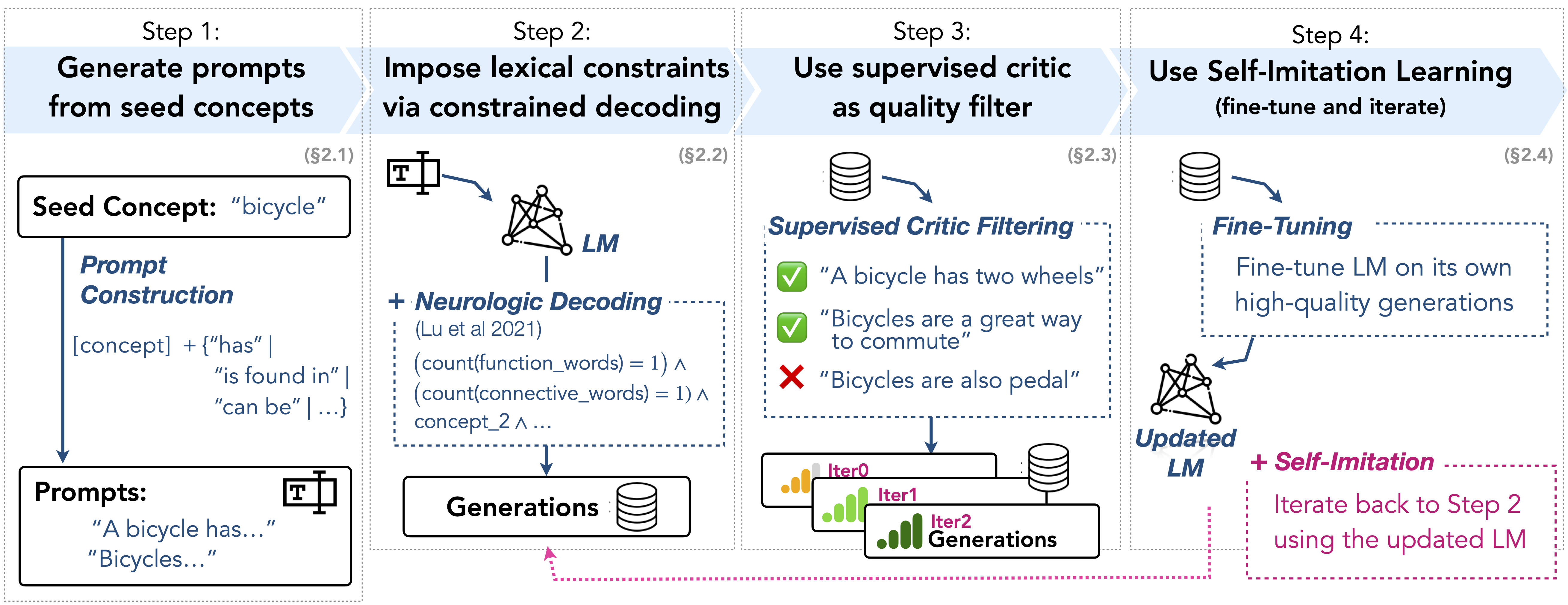
Abstract
Commonsense capabilities of pre-trained language models dramatically improve with scale, leading many to believe that scale is the only winning recipe. But is it? Here, we investigate an alternative that a priori seems impossible: can smaller language models (e.g., GPT-2) win over models that are orders of magnitude larger and better (e.g., GPT-3), if powered with novel commonsense distillation algorithms?
The key intellectual challenge is to design a learning algorithm that achieve a competitive level of commonsense acquisition, without relying on the benefits of scale. In particular, we study generative models of commonsense knowledge, focusing on the task of generating generics, statements of commonsense facts about everyday concepts, e.g., birds can fly.
We introduce I2D2, a novel commonsense distillation framework that loosely follows the Symbolic Knowledge Distillation of West et al. but breaks the dependence on the extreme-scale teacher model with two innovations: (1) the novel adaptation of NeuroLogic Decoding to enhance the generation quality of the weak, off-the-shelf language models, and (2) self-imitation learning to iteratively learn from the model's own enhanced commonsense acquisition capabilities. Empirical results suggest that scale is not the only way, as novel algorithms can be a promising alternative. Moreover, our study leads to a new corpus of generics, Gen-A-tomic, that is the largest and highest quality available to date.
How to cite this work
@inproceedings{Bhagavatula2023I2D2,
title={I2D2: Inductive Knowledge Distillation with NeuroLogic and Self-Imitation},
author={Chandra Bhagavatula, Jena D. Hwang, Doug Downey, Ronan Le Bras, Ximing Lu, Lianhui Qin, Keisuke Sakaguchi, Swabha Swayamdipta, Peter West, Yejin Choi},
booktitle={ACL},
year={2023}
}
Authors
Chandra Bhagavatula1, Jena D. Hwang1, Doug Downey1,2, Ronan Le Bras1, Ximing Lu1,5, Lianhui Qin5, Keisuke Sakaguchi4, Swabha Swayamdipta3, Peter West1,5, Yejin Choi1,5
1Allen Institute for Artificial Intelligence, 2Northwestern University, 3University of Southern California, 4Tohoku University and 5University of Washington